클라우드 모니터링 핵심 가이드: 7가지 필수 지표로 비용·성능·가용성을 한 번에
왜 지금, 클라우드 모니터링이 비즈니스 성패를 좌우할까?
- 클라우드 모니터링은 단순한 지표 수집이 아니라, 비용 누수 차단과 성능 보장, 사고 대응 시간을 줄이는 운영 전략이에요. 특히 멀티 클라우드 시대에는 표준화된 핵심 지표로 상태를 한눈에 보는 것이 중요하죠.
- 이 글에서는 AWS·GCP·Azure 공통으로 바로 적용 가능한 7가지 필수 지표와, 대시보드/알림 설계, SLO 운영 팁까지 단계별로 정리했어요. 링크와 예시를 따라오면 오늘 바로 적용할 수 있어요.
- 오픈소스 스택을 쓰신다면 시각화와 경보 자동화를 함께 도입해 보세요. Grafana·Prometheus 안내서

클라우드 모니터링 7가지 필수 지표 개요
- 가용성(Availability/SLA): 서비스가 정상 응답하는 비율. SLO·에러버짓의 기준이 됩니다.
- 지연시간(Latency p95/p99): 사용자가 체감하는 응답 시간의 상위 퍼센타일. 초단위보다 밀리초 단위로 추적하세요.
- 오류율(Error rate): HTTP 5xx/특정 예외 비율. 배포 직후 스파이크 감지가 핵심입니다.
- 처리량(Throughput/Traffic): 초당 요청/메시지/쿼리 수. 과부하·스케일링 신호를 제공합니다.
- 포화도(Saturation): CPU/메모리/디스크/네트워크 사용률과 큐 길이. 병목의 직접 지표예요.
- 비용·예산 소진(Burn rate): 일·주간 비용 추세, 단가(CPU-hr, 요청당 비용). 낭비 탐지의 출발점입니다.
- 쿼터·한도(Quota/Rate limit): API/서비스별 한도 근접도. 갑작스런 장애를 예방하죠.
- 현업에서도 요구사항의 80%는 위 7가지로 해결됩니다. 채용 JD에서도 유사한 역량을 요구하고 있어요. 모니터링 역량 JD 예시

각 지표를 AWS·GCP·Azure에서 바로 측정하는 법
1) 가용성
- AWS: CloudWatch Synthetics, ALB Target HealthyHostCount로 엔드포인트 생존 확인.
- GCP: Uptime Checks + Alerting 정책으로 글로벌 헬스 체크 구성.
- Azure: Application Insights Availability 테스트로 지역별 모니터링.
- 팁: 에러버짓 정책을 정의하고, 버짓 소진 속도에 따라 배포 프리즈를 자동화하세요. 클라우드 모니터링 대시보드 첫 줄에 배치하면 효과가 커요.
2) 지연시간(p95/p99)
- AWS: API Gateway Latency, ELB TargetResponseTime, RDS/ElastiCache 쿼리 지연.
- GCP: Cloud Load Balancing latency, Cloud Run/Functions request latency.
- Azure: App Insights request duration, Cosmos DB RU 지연.
- 경보 기준: p95 300ms↑ 또는 p99 1s↑를 기준으로 서비스 특성에 맞게 튜닝하세요. 클라우드 인사이트 더 보기
3) 오류율
- AWS: 5xxError, Lambda Errors, Step Functions Failed 상태 모니터링.
- GCP: Error Reporting, Cloud Run/Functions error ratio.
- Azure: App Insights 실패 요청 비율, AKS Pod 재시작 횟수.
- 릴리스 직후 15분 스파이크를 별도 경보로 분리하면 노이즈를 크게 줄일 수 있어요.
4) 처리량
- AWS: ALB RequestCount, Kinesis/ MSK 메시지 처리량.
- GCP: Pub/Sub 메시지 초당 처리, GCLB RPS.
- Azure: Event Hubs Throughput, App Service Requests/Sec.
- 스케일 룰: RPS와 지연의 상관을 보고 HPA/자동 스케일링 임계값을 산정하세요. 관련 직무 요구사항 참고
5) 포화도
- AWS: EC2 CPUUtilization/Memory, EBS BurstBalance, ELB SpilloverCount.
- GCP: GCE CPU/메모리, Cloud SQL 커넥션/버퍼 캐시, GKE 노드/파드 포화.
- Azure: VM CPU ready/메모리 압력, Disk QDepth, AKS 노드/Pod Utilization.
- 큐 지표(대기열 길이, 처리 지연)는 포화도의 직격 신호예요. 클라우드 모니터링 패널에 병목 원인 옆에 배치하세요.
6) 비용·버짓 소진
- AWS: Cost Explorer + Budgets 알림, 태그/Cost Allocation로 팀별 단가 추적.
- GCP: Cloud Billing Export(BigQuery) + Data Studio 대시보드.
- Azure: Cost Management + Budget Alerts, Resource Tagging.
- 권장: 요청당 비용, 사용자당 비용, 테넌트별 비용을 함께 보세요. 비용 최적화 아이디어
7) 쿼터·레이트 리밋
- AWS: Service Quotas/Trusted Advisor로 한도 근접도 추적.
- GCP: Quotas API로 자동 점검, 임계치 초과시 알림.
- Azure: Subscription/Resource 쿼터 사용률 파악, 사전 증가 요청.
- 배포 전·대규모 이벤트 전에는 반드시 리밋 체크를 배포 파이프라인에 넣으세요. 클라우드 모니터링 체크리스트의 필수 항목입니다.
벤더 매핑 한눈에 보기
| 지표 | AWS | GCP | Azure |
| 가용성 | CloudWatch Synthetics | Uptime Checks | App Insights Availability |
| 지연시간 | ALB Latency, API GW | Cloud Run/Load Balancer | Request duration |
| 오류율 | 5xxError, Lambda Errors | Error Reporting | Failed Requests |
| 처리량 | RequestCount, Kinesis | Pub/Sub throughput | Requests/Sec |
| 포화도 | CPU/Mem/EBS Queue | GCE/Cloud SQL/GKE | VM/AKS Utilization |
| 비용 | Cost Explorer/Budgets | Billing Export | Cost Management |
| 쿼터 | Service Quotas | Quotas API | Subscription Quotas |
- 지표 이름은 서비스별로 다르지만, 의미는 동일해요. 공통 KPI로 표준화하면 멀티 클라우드 운영이 쉬워집니다. 기초 개념 더 학습
알림·SLO·플레이북: 노이즈 없이 정확하게
- 경보 설계: 지연 p95와 오류율에 복합 조건을 걸고, 5분 이동평균 + 데드맨 스위치(데이터 미수신)로 보강하세요.
- SLO/에러버짓: 월간 99.9% SLO라면 에러버짓 43분. 클라우드 모니터링 패널에 실시간 소진율을 표시하면 의사결정이 빨라져요.
- 플레이북: 지표별 원인-조치-롤백 단계를 표준화하고, 링크로 점프하도록 만드세요. 운영 자동화 아이디어
- 온콜 운영: 중대도(Critical/High/Medium)를 나누고, 업무시간 외엔 중요 경보만 울리도록 사일런싱 규칙을 둡니다. 현업 Q&A 참고

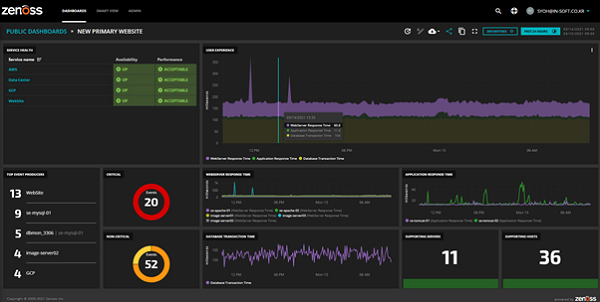
대시보드 구성 팁: 한 화면에 핵심이 다 보이도록
- 상단: 가용성, 지연 p95, 오류율(지난 1시간/24시간), 에러버짓 소진률.
- 중단: 처리량과 포화도(서비스·DB·캐시·큐), 리전/존별 히트맵.
- 하단: 비용 추세, 단가, 버짓 대비 소진율, 쿼터 근접도.
- 드릴다운: 패널 클릭 시 로그/트레이스/배포 히스토리로 이동. 클라우드 모니터링과 배포 파이프라인을 링크로 묶으세요. 대시보드 설계 인사이트
비용 최적화 워크플로우
- 태깅 표준화: 서비스/팀/환경/제품 태그로 비용 분류. 단가(요청/사용자/테넌트) 지표를 대시보드에 고정하세요.
- 권장 조치: Rightsizing, 예약 인스턴스/Savings Plans, 스토리지 계층화, 데이터 전송 비용 점검.
- 경보: 일간 버짓 소진률(예: 1.5배↑), 특정 태그 비용 급등을 별도 채널로 알림. 참고: 보안 관점 고려
운영 자동화와 모범 사례
- IaC와 함께: 대시보드/알림을 코드로 버전관리(Terraform/ARM). 동일 서비스가 리전에 늘어도 일관성을 보장해요.
- 관측성 통합: 메트릭·로그·트레이스를 상호 링크. 오류율 스파이크 → 트레이스 샘플 → 문제 릴리스 커밋으로 3클릭 내 확인.
- 런북·사후 분석: 경보에 런북 링크를 걸고, 인시던트 종료 후 타임라인/근본원인/행동 항목을 기록하세요.
- 보안 지표: IAM 정책 변경, 방화벽 룰 수정, 취약 CVE 노출도도 핵심 패널로 함께 관리하면 좋아요. 디지털 트렌드 살펴보기
“보여야 고칠 수 있다. 측정은 개선의 출발점이며, 좋은 클라우드 모니터링은 팀의 공용 언어가 됩니다.”
마무리: 오늘 바로 적용할 실행 체크리스트
- 7가지 지표로 SLI를 정의하고, 서비스별 SLO·에러버짓을 확정하세요. 클라우드 모니터링 대시보드 상단에 고정해 매일 확인하세요.
- 경보는 복합 조건·데드맨·사일런싱으로 노이즈를 줄이고, 플레이북 링크로 MTTR을 단축하세요.
- 비용 지표는 단가 관점으로 전환하고, 버짓 소진률 경보를 팀 태그 단위로 분리하세요.
- 대시보드·알림을 IaC로 버전관리하고, 배포와 모니터링 히스토리를 연결해 릴리스 리스크를 낮추세요. 클라우드 심화 아카이브
- 정기 점검: 지연 p95, 오류율, 포화도, 비용 버짓, 쿼터 근접도를 주간 리뷰로 고정하세요. 클라우드 모니터링 문화가 팀의 민첩성을 만듭니다.
메시지가 발송되었음
