데이터베이스 인덱스 7가지 핵심 원리: 쿼리 속도 향상·성능 최적화 실무 가이드
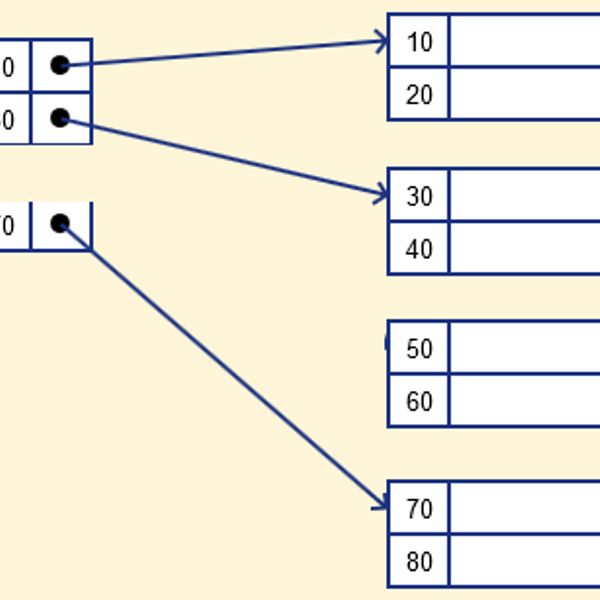
- 데이터베이스 인덱스는 책의 목차처럼 원하는 행을 빠르게 찾도록 도와주는 자료구조예요. 잘 설계하면 디스크 접근과 비교 연산을 크게 줄여 쿼리 지연을 체감적으로 낮출 수 있어요. 반대로 무분별한 인덱스는 쓰기 비용을 폭증시켜 전체 성능을 해치기도 하죠.
- 이 글에서는 실무에서 꼭 알아야 하는 7가지 핵심 원리를 친근하게 풀어 설명하고, 워크로드별 설계 팁, 실행계획 읽는 법, 안티패턴까지 함께 정리해 드릴게요. 중간중간 내부/외부 레퍼런스도 함께 남겨둘게요. IT 기초지식 더 보기
1) 선택도·카디널리티: 인덱스 효율의 시작
- 데이터베이스 인덱스 성능은 선택도(Selectivity)와 카디널리티(Cardinality)에 달려 있어요. 값의 종류가 다양하고 특정 조건으로 결과가 충분히 좁혀질수록 인덱스는 빛을 발합니다. 반대로 boolean 같은 저선택도 컬럼은 단독 인덱스로 효과가 약하죠.
- 실무 팁: 카테고리(boolean) + 생성일(date)처럼 저선택도 + 범위 조합은 단독 인덱스보다는 복합 인덱스로 묶어야 옵티마이저가 범위를 먼저 좁히고 후속 필터를 적용하기 쉬워요.
- 배경 지식이 더 필요하다면 개념 정리를 참고하세요. 데이터베이스 기본 개념
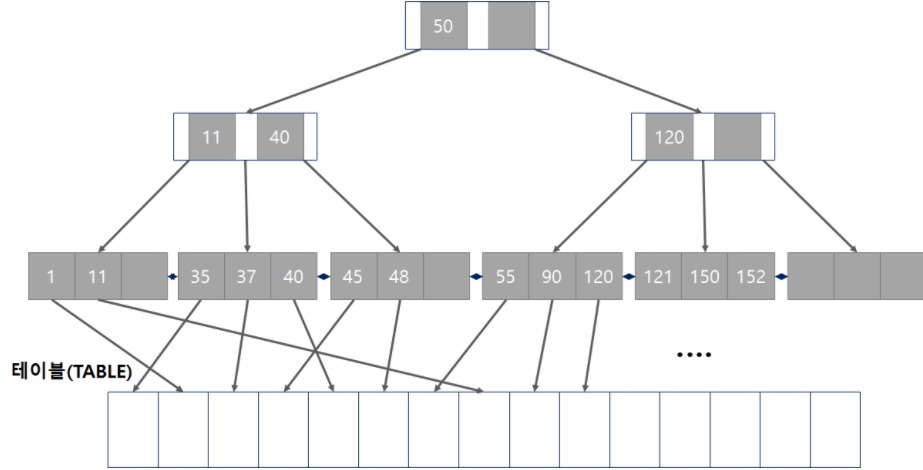
2) B-Tree/B+Tree 구조: 페이지·노드·높이
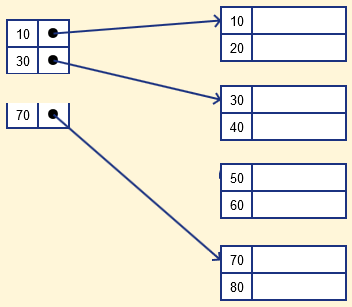
- 대부분의 데이터베이스 인덱스는 B-Tree(B+Tree)로 구현돼요. 분기 노드와 리프 노드로 이뤄지며, 키가 정렬된 상태로 저장됩니다. 트리 높이가 낮고 각 노드의 팬아웃이 크면 디스크 I/O가 줄어들죠.
- 리프 노드가 정렬된 덕분에 범위 스캔(>, BETWEEN)은 매우 빠르게 처리됩니다. 반대로 와일드카드 접두(%term)는 정렬 순서를 활용하지 못해 풀스캔 위험이 커져요.
- B-Tree의 동작을 다루는 입문 자료도 함께 보세요. B-Tree 개념 정리 | 개발 카테고리
3) 정렬성·범위 스캔·정렬 회피
- ORDER BY, GROUP BY가 인덱스 정렬 순서와 일치하면 데이터베이스 인덱스만으로 결과를 만들어 파일 정렬을 피할 수 있어요. 이때 쿼리의 정렬 컬럼과 인덱스 컬럼 순서가 일치하도록 설계하는 게 핵심입니다.
- 범위 조건이 등장하면 그 뒤 컬럼은 정렬 보장이 끊어지니, 복합 인덱스의 순서를 정확히 결정해야 해요. 예) (status, created_at DESC)로 최근 데이터만 빠르게 뽑기.
- 최신 동향 관련 읽을거리도 함께 참고하세요. 관련 인사이트
4) 복합 인덱스: Left-most Rule과 컬럼 순서
- 복합 인덱스는 왼쪽 접두 규칙(Left-most prefix)을 따릅니다. (A,B,C) 인덱스는 A, (A,B), (A,B,C) 쿼리에 유효하지만 (B)만 쓰는 쿼리에는 비효율적이에요. 그래서 쿼리 패턴을 기준으로 컬럼 순서를 정해야 합니다.
- 데이터베이스 인덱스 설계 시 선택도가 높은 컬럼을 앞에 두거나, where 조건에 가장 자주 등장하는 컬럼을 먼저 두는 전략이 일반적이에요. 단, 정렬·그룹 조건이 있다면 그 순서도 함께 고려해야 합니다.
- 팀 표준과 사례는 내부 문서·카테고리에 정리해 두면 좋아요. IT 동향 보기

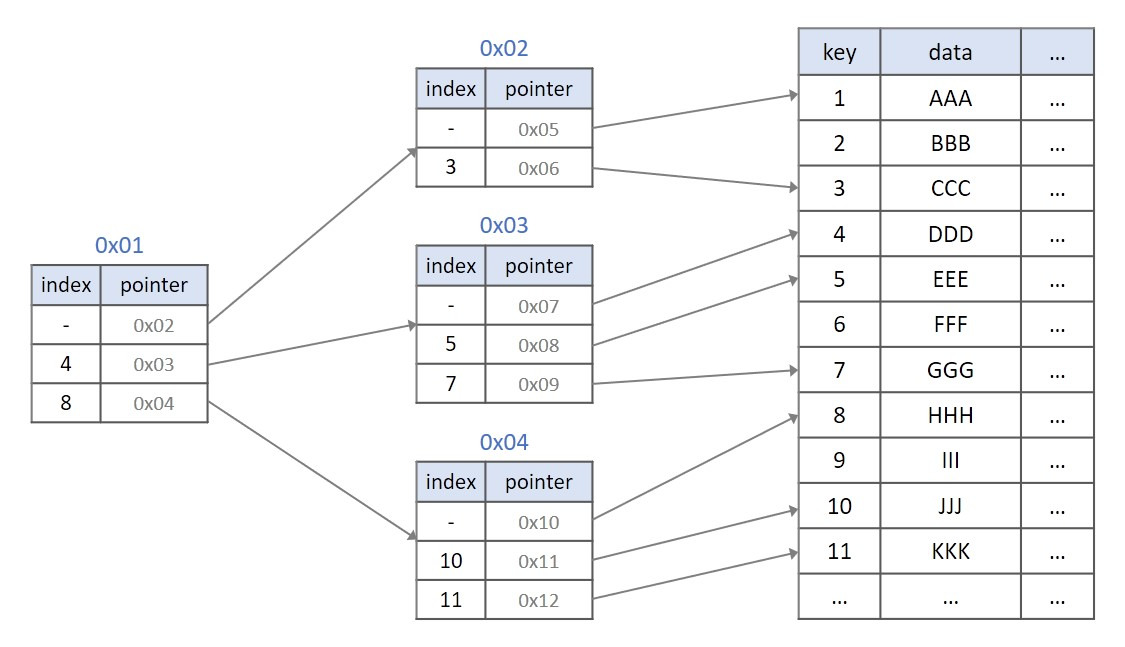
5) 커버링 인덱스: 테이블 접근을 없애는 기술
- 쿼리에 필요한 컬럼이 모두 인덱스에 포함되어 있으면 커버링 인덱스가 됩니다. 이 경우 스토리지 테이블로 내려가지 않아 I/O가 크게 줄어요. SELECT list에 꼭 필요한 컬럼만 포함해 인덱스 크기를 통제하세요.
- 예: (status, created_at, id) 인덱스로 status=‘OK’ AND created_at>=… 조건과 id만 조회하는 요청을 커버링할 수 있어요. 이 방식은 대량 읽기 트래픽을 처리하는 API에서 매우 강력합니다.
- 관계형 DB의 전반 개념 정리는 아래 외부 리소스를 참고하세요. 오라클 DB 개요
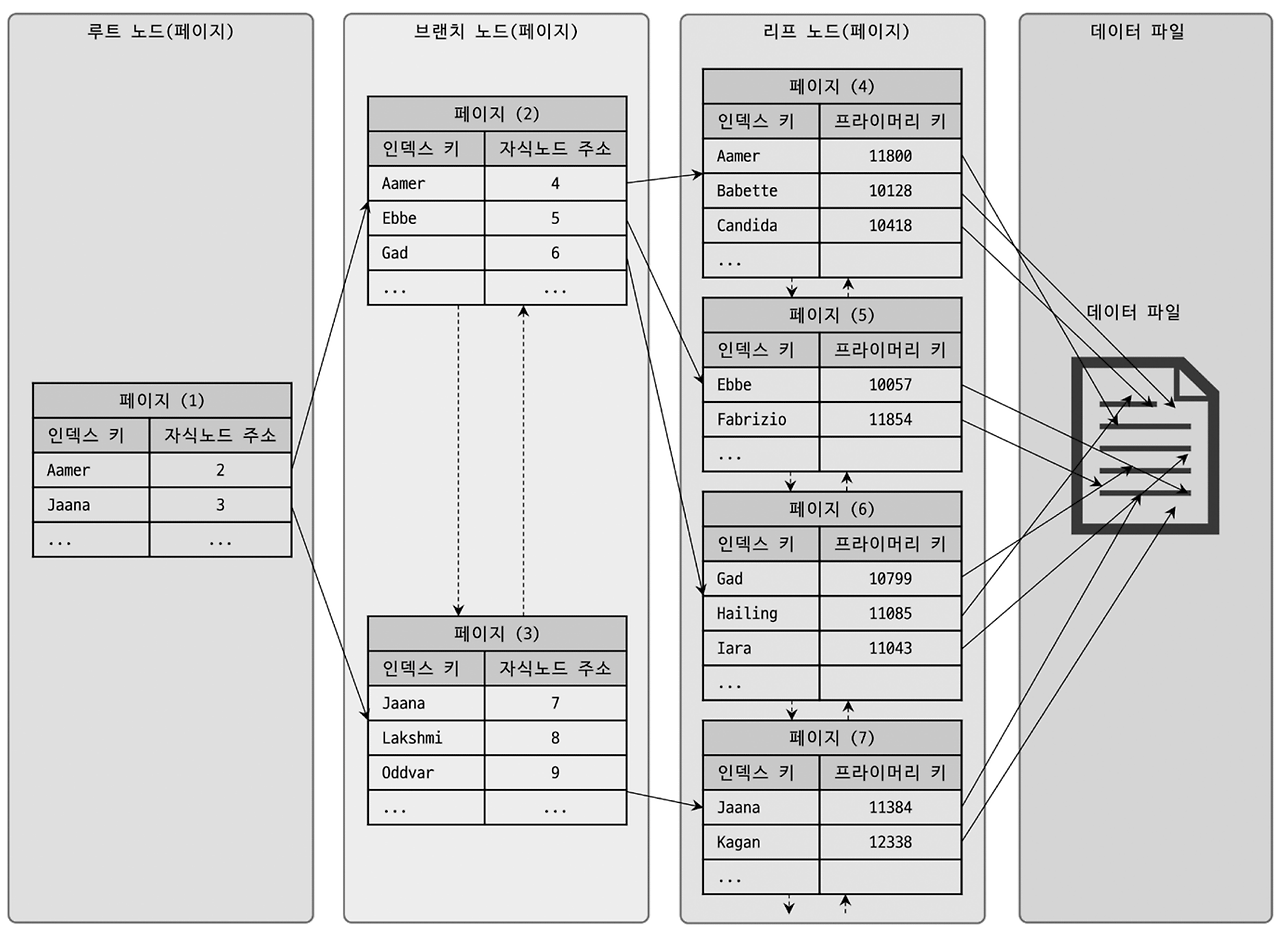
6) 클러스터형 vs 보조 인덱스: 스토리지 레이아웃 이해
- InnoDB처럼 클러스터형 인덱스를 쓰는 엔진에서는 기본키가 실제 레코드의 물리적 순서를 규정합니다. 세컨더리 인덱스는 리프에 기본키를 보관하므로, 결국 더블 룩업이 발생할 수 있어요.
- 따라서 데이터베이스 인덱스 전략에서는 기본키 선택이 중요합니다. 긴 UUID를 PK로 쓰면 인덱스가 비대해지고 페이지 분할이 잦을 수 있어요. 단조 증가 타입(예: ULID의 시간 정렬 버전)이나 BIGINT 시퀀스는 페이지 분할을 줄이는 데 유리합니다.
- 조금 다른 관점의 해석과 트렌드는 내부 아카이브를 함께 참고해 보세요. 디지털 트렌드

7) 유지비용: 쓰기 증폭·통계·옵티마이저
- 인덱스는 쓰기 시에도 갱신돼야 하므로 INSERT/UPDATE/DELETE가 많은 시스템에서는 과도한 인덱스가 병목이 됩니다. 업무 KPI별로 “읽기 성능”과 “쓰기 비용”을 균형 있게 최적화해야 해요.
- 옵티마이저는 통계를 바탕으로 실행계획을 고릅니다. 통계가 오래되면 데이터베이스 인덱스를 제대로 활용하지 못할 수 있으니, 통계 갱신 주기를 운영 지표에 맞춰 자동화하세요.
- 케이스 스터디 형식의 글도 도움 됩니다. 운영 사례 읽기
지표 없이 최적화는 어렵습니다. 실행계획·지연 시간·I/O·캐시 히트율을 보며 데이터베이스 인덱스 효과를 입증하세요.
실무 체크리스트와 안티패턴
- 쿼리 패턴 수집: 80% 트래픽을 차지하는 엔드포인트/리포트를 먼저 최적화해요. 내부 가이드도 함께 확인해 보세요. 생산성 팁 모음
- 인덱스 최소화: 읽기 성능을 위해서라도 중복 인덱스는 과감히 제거합니다. (A,B)와 (A) 중복 여부를 점검하세요.
- 접두 와일드카드 금지:
%term은 정렬을 못 타요. 가능하면 접미 검색 또는 전문 검색엔진을 고려하세요. - 데이터 타입 일치: 조건 컬럼과 바인드 변수 타입이 다르면 인덱스가 무효화될 수 있어요.
- 커버링 우선: 고빈도 읽기는 커버링 인덱스로 I/O를 줄입니다.
실행계획 빠르게 읽는 법
| 항목 | 핵심 해석 |
| type | ALL(풀스캔) < index < range < ref < eq_ref < const 순으로 우수 |
| key/key_len | 선택된 데이터베이스 인덱스와 활용된 길이 |
| rows | 예상 스캔 행 수. 수치가 높다면 선택도·조건식을 재점검 |
| Extra | Using index(커버링), Using where(후속 필터), Using filesort(정렬 회피 실패) |
- 특정 엔진의 차이는 문서로 보완하세요. MySQL 인덱스 가이드
워크로드별 인덱싱 전략
- OLTP(거래형): 지연 민감. where 조건과 조인 키 위주로 최소 인덱스, 쓰기 경로 최적화. 최근 순 조회라면 (status, created_at DESC) 같은 복합 인덱스를 고려.
- OLAP/리포트: 배치·긴 쿼리 허용. 데이터베이스 인덱스 대신 파티셔닝/요약 테이블/머티리얼라이즈드 뷰가 더 효과적일 때가 많아요.
- 엔드투엔드 최적화 흐름도는 아래 글도 함께 보세요. 실무 최적화 흐름 | 클라우드 관점

마무리: 작게 시작해 반복 개선하세요
- 핵심은 간단해요. 자주 쓰는 쿼리를 파악하고, 선택도 높은 조건부터 데이터베이스 인덱스를 설계하세요. 실행계획으로 가설을 검증하고, 쓰기 비용을 모니터링하면서 중복 인덱스를 꾸준히 정리하면 됩니다.
- 정리: (1) 선택도 (2) B-Tree (3) 정렬성 (4) 복합 순서 (5) 커버링 (6) 클러스터형/보조 (7) 유지비용. 이 7가지만 정확히 이해해도 대부분의 병목은 해결돼요.
- 추가로 더 읽어볼 만한 개론 링크도 남겨둘게요. 커뮤니티 토픽 | AI와 DB 성능
메시지가 발송되었음
